
 Author: Taras Denysenko, Software Engineer
Author: Taras Denysenko, Software Engineer
When installing a new SugarCRM instance with MS SQL Server, it is highly recommended to ensure that the database for SugarCRM has a Windows collation set, otherwise it might run into heavy performance issues on large amounts of data due to indexes not working as intended. To that end, unless your MS SQL Server instance has a Windows collation specified in its settings, it would be best to manually create a database to be used for installation, configuring it to use one of collations without the SQL_ prefix, instead of relying on SugarCRM installer to create a new database for you.
Our experience has taught us that SugarCRM performance and user experience in a large part depend on decisions made at installation time. In particular, when it comes to setting up SugarCRM with MS SQL Server as RDBMS, there is one such decision, which is often reduced to an afterthought, but may prove a crucial one in the long run. I am referring, of course, to accepting the license agreement. (Ba-dum-tisssh…) Not really. Actually, I am referring to the choice of DB collation.
That’s right! A humble collation has more to it than simply defining whether “ch” comes before or after “cz” and whether “Turkey” is the same as “turkey”. With the way SugarCRM is designed, it turns out that collation also determines whether it takes several seconds or several hours to display a record’s detail view, given a table with tens of millions of records. How can it have such a dramatic effect?
To avoid boring you with details, I’ll try to give you an answer as concise as possible. Here goes:
- MS SQL Server provides two kinds of column types for storing strings – non-Unicode (CHAR, VARCHAR, TEXT) and Unicode (NCHAR, NVARCHAR, NTEXT). The former kind cannot be used to store arbitrary Unicode strings but, generally speaking, needs less space, the latter kind is capable of storing Unicode at the cost of a larger memory footprint.
- There are 2 kinds of collations in MS SQL Server – SQL (those with SQL_ prefix) and Windows ones (those without). The latter kind uses the same rules of comparison for both non-Unicode and Unicode values, the former uses one set of rules for non-Unicode and another for Unicode. Collations are set at server, database, column and expression levels. If no collation is set explicitly when a column is created, it gets assigned database’s collation. By the same principle, database gets assigned server’s collation, if none is specified at the time of its creation. Windows collations are recommended by Microsoft for new applications, while SQL ones are still kept around for backwards compatibility.
- Under an SQL collation, if a query contains a Unicode literal, which is checked against a non-Unicode column, every value from said column needs to be promoted to Unicode to allow for comparisons to take place. Consequently, even if there is an index over said column, it will not kick in and a slow Index Scan (slow sequential reading of all the values in the table) will have to be performed instead of an Index Seek (a fast index lookup). This conversion cannot be done the other way around, since, in general, converting Unicode string to non-Unicode might lead to data loss. Under a Windows collation, on the other hand, since the same set of rules is used for both kinds of strings, an Index Seek is performed regardless.
- SugarCRM uses Unicode columns for all of the strings it keeps in its database, except for records’ IDs – those are stored in non-Unicode VARCHAR columns.
- In all of its queries SugarCRM sends to SQL Server, all of the strings are specified as Unicode literals. This includes strings in WHERE clauses, which are checked against ID columns, as in the following example:
1 2 3 | SELECT * FROM sugarcrm.dbo.accounts WHERE id = N'1a793a5d-516e-432d-b67d-e812c36adaef' |
As you can see, even though the ID column is non-Unicode, the literal checked against it is Unicode (marked as such by its N prefix). Given an SQL collation, we have ourselves a textbook example of the problem, described in item #3. What’s even more unfortunate is that looking up a record by its ID, which is exactly what this example does, is not what one would call an uncommon operation. Multiple queries such as this one are routinely sent by SugarCRM during a single page load, which, given a sufficiently large table, translates into minutes upon minutes of waiting.
One of our customers, Admiral Markets company, requested assistance with their Sugar instance, which had been experiencing heavy SugarCRM performance issues seemingly for no reason. After thorough investigation we managed to find the culprit – an SQL collation, used by this instance’s database in MS SQL Server. As you may recall from item #2 on our list, a newly created column gets its database’s collation by default, unless another one is explicitly provided. When creating columns, SugarCRM does not specify the collation to use, therefore, in case of our customer, all of them shared the same SQL collation, specified at database level and SugarCRM ran face first into the problem we discussed, where even a simple query triggered an index scan.
How do we ensure, at installation time, that such performance issues do not befall our SugarCRM instance later down the line, when an enormous number of records is stored in its database? As you’ve probably figured out, we need to make sure that our database uses one of Windows collations – sounds simple enough. Let’s open up SugarCRM installer and input the settings accordingly for the new database.
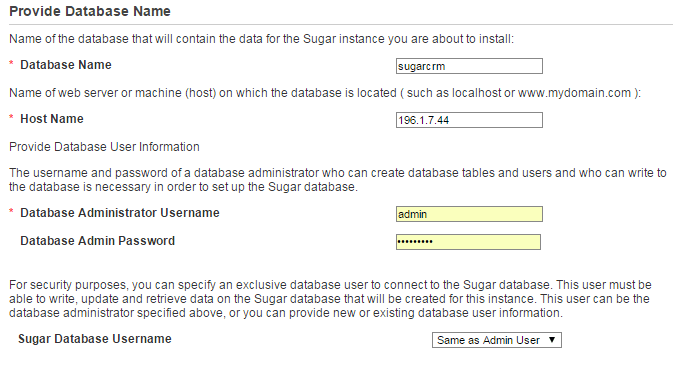
Right!… Now, hang on a second, how do I choose the collation? Well, it turns out that SugarCRM installer absentmindedly forgets to offer this choice. Assuming the database with the name we specified does not yet exist, what happens when we proceed with the installation? Installer will simply create a new database without explicitly setting its collation and so, by default, it will be given the collation of the server. It may turn out to be a Windows collation – in this case, we are in luck.
If, on the other hand, an SQL collation is specified at server level, we’ll have to manually create a database for SugarCRM to use via SQL Server Management Studio or your preferred database UI, choosing one of collations without the SQL_ prefix, instead of server default.
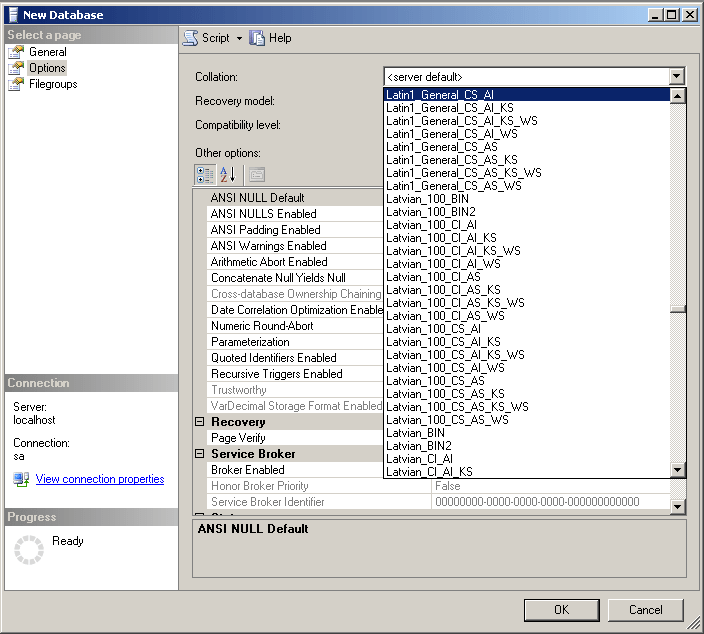
Having done so, we go back to SugarCRM installer and use the name of our manually created database in its database settings. Now when we proceed, the installer will warn us that the database already exists and that all of the data it contains will be destroyed. After we accept our fate, the installation will continue in its normal manner. Once it’s done, we’ll have a brand new SugarCRM instance, protected by our smart planning against dips in performance, caused by gratuitous index scans in the database. A happy ending indeed.
Hopefully, this guide gave you some insight into one of the pitfalls in the arrangement of a happy marriage between SugarCRM and MS SQL Server. If you’re interested in the topic, here you can also read “How to Optimize SugarCRM by Choosing MS SQL Server Collations”: